
Open Source Projects
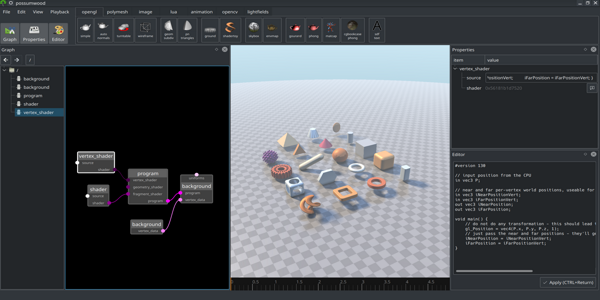
Possumwood is a graph-based procedural authoring tool, in concept not dissimilar to popular CG packages like Houdini, Blender or Maya. It is intended to serve as a sandbox for computer graphics algorithms and libraries, providing a user-friendly and coding-free UI for libraries that would otherwise be inaccessible for an average user.
Industry Talks

DNEG’s in-house fur software, Furball, has been in continuous pro- duction use since 2012. During this time it has undergone significant evolution to adapt to the changing needs from production. We discuss how recent work on films such as Avengers: Endgame and Togo has led to a complete shift in the focus of our fur tools. This has helped us scale up to meet the requirements of ever more fur-intensive shows, while also opening up exciting opportunities for future development.

The primary challenge at the heart of Visual Effects lies in the ability to translate the director’s creative brief into compelling visuals using a combination of art and technology. In the case of Venom a key requirement was to keep the character design as faithful to the comic books as possible. This talk describes the challenges tackled by the Rigging, Effects, and R&D departments at DNEG in order to bring this classic antihero to life in a photorealistic manner.
When constructing shots of non-human crowds that exhibit com- plex behaviors, the standard approach based on the well-established rules of boid simulation is likely to fall short when used for a group of characters with łintent”. In Pacific Rim Uprising, Double Negative VFX tackled the challenge of producing a large crowd of highly ar- ticulated robotic creatures performing the complex and coordinated task of łassembling” a mega-Kaiju. This task required a number of innovative approaches to both crowd authoring and rendering, and close collaboration between the RnD and artists.

When constructing shots of non-human crowds that exhibit complex behaviors, the standard approach based on the well-established rules of boid simulation is likely to fall short when used for a group of characters with "intent". In Pacific Rim Uprising, Double Negative VFX tackled the challenge of producing a large crowd of highly articulated robotic creatures performing the complex and coordinated task of "assembling" a mega-Kaiju. This task required a number of innovative approaches to both crowd authoring and rendering, and close collaboration between the RnD and artists.

The complexity of crowd shots can vary greatly, from simple vignetting tasks that add life to an environment, to large and complex battle sequences involving thousands of characters. For this reason, a “one size fits all” crowd solution might not be optimal, both in terms of design and usability, but also allocation of crew. In this talk we present a suite of tools, developed across multiple platforms, each optimised for specific crowd tasks. These are underpinned by a data interchange library to allow for modification at any stage of the pipeline.

Large virtual worlds require large virtual crowds. One of the main themes of Exodus is a clash of ancient civilisations, represented via virtual background crowds in a large number of shots. To generate these crowds, we used an in-house crowd solution, whose development was aimed at background crowds for photorealistic scenes.
VFX crowds are subject to specific requirements, because they are used to enliven and extend crowd shots captured by a camera. Each shot consists of three layers – hero characters (usually real actors shot on set), crowd-anim (hand-animated) and procedural background crowds. To retain scene consistency, the background crowds must join seamlessly with other layers.
Academic Publications

Real-time computer animation is an essential part of modern computer games and virtual reality applications. While rendering provides the main part of what can be described as “visual experience”, it is the movement of the characters that gives the final impression of realism. Unfortunately, realistic human animation has proven to be a very hard challenge.
Some fields of computer graphics have a compact and precise mathematical description of the underlying principles. Rendering, for example, has the rendering equation, and each realistic rendering technique provides its approximate solution. Due to its highly complex nature, character animation is not one of these fields. That is one of the reasons why even single character animation still provides significant research challenges. The challenges posed by a crowd simulator, required to populate a virtual world, are even larger. This is not only because of the large number of simultaneously displayed characters, which necessitate the use of level-of-detail approaches, but also the requirement of reactive behaviour, which can be provided only by a complex multi-level planning module.
In this thesis, we address the problem of human animation for crowds as a component of a crowd simulator.

When animating virtual humans for real-time applications such as games and virtual reality, animation systems often have to edit motions in order to be responsive. In many cases, contacts between the feet and the ground are not (or cannot be) properly enforced, resulting in a disturbing artifact know as footsliding or footskate. In this paper, we explore the perceptibility of this error and show that participants can perceive even very low levels of footsliding (<21mm in most conditions). We then explore the visual fidelity of animations where footskate has been cleaned up using two different methods. We found that corrected animations were always preferred to those with footsliding, irrespective of the extent of the correction required. We also determined that a simple approach of lengthening limbs was preferred to a more complex approach using IK fixes and trajectory smoothing.

In order to simulate plausible groups or crowds of virtual characters, it is important to ensure that the individuals in a crowd do not look, move, behave or sound identical to each other. Such obvious `cloning’ can be disconcerting and reduce the engagement of the viewer with an animated movie, virtual environment or game. In this paper, we focus in particular on the problem of motion cloning, i.e., where the motion from one person is used to animate more than one virtual character model. Using our database of motions captured from 83 actors (45M and 38F), we present an experimental framework for evaluating human motion, which allows both the static (e.g., skeletal structure) and dynamic aspects (e.g., walking style) of an animation to be controlled. This framework enables the creation of crowd scenarios using captured human motions, thereby generating simulations similar to those found in commercial games and movies, while allowing full control over the parameters that affect the perceived variety of the individual motions in a crowd. We use the framework to perform an experiment on the perception of characteristic walking motions in a crowd, and conclude that the minimum number of individual motions needed for a crowd to look varied could be as low as three. While the focus of this paper was on the dynamic aspects of animation, our framework is general enough to be used to explore a much wider range of factors that affect the perception of characteristic human motion.
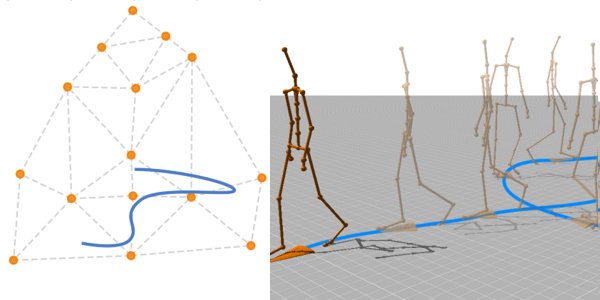
The animation of hundreds or even thousands of simultaneously displayed individuals is challenging because of the need for both motion variety and efficient runtime processing. We present a middle level-of-detail animation system optimised for handling large crowds which takes motion-capture data as input and automatically processes it to create a parametric model of human locomotion. The model is then used in a runtime system, driven by a linearised motion blending technique, which synthesises motions based on information from a motion-planning module. Compared to other animation methods, our technique provides significantly better runtime performance without compromising the visual quality of the result.
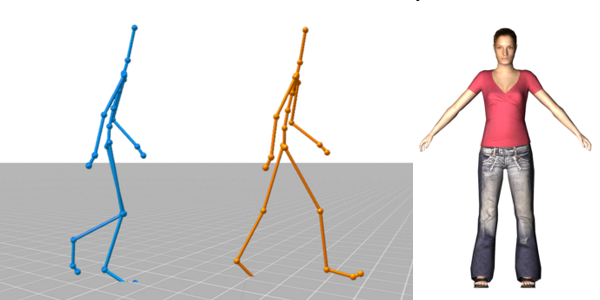
Understanding the perception of humanoid character motion can provide insights that will enable realism, accuracy, computational cost and data storage space to be optimally balanced. In this sketch we describe a preliminary perceptual evaluation of human motion timewarping, a common editing method for motion capture data. During the experiment, participants were shown pairs of walking motion clips, both timewarped and at their original speed, and asked to identify the real animation. We found a statistically significant difference between speeding up and slowing down, which shows that displaying clips at higher speeds produces obvious artifacts, whereas even significant reductions in speed were perceptually acceptable.

This work addresses the challenge of synchronizing multiple sources of visible and audible information from a variety of devices, while capturing human motion in realtime. Video and audio data will be used to augment and enrich a motion capture database that will be released to the research community. While other such augmented motion capture databases exist [Black and Sigal 2006], the goal of this work is to build on these previous works. Critical areas of improvement are in the synchronization between cameras and synchronization between devices. Adding an array of audio recording devices to the setup will greatly expand the research potential of the database, and the positioning of the cameras will be varied to give greater flexibility. The augmented database will facilitate the testing and validation of human pose estimation and motion tracking techniques, among other applications. This sketch briefly describes some of the interesting challenges faced in setting up the pipeline for capturing the synchronized data and the novel approaches proposed to solve them.
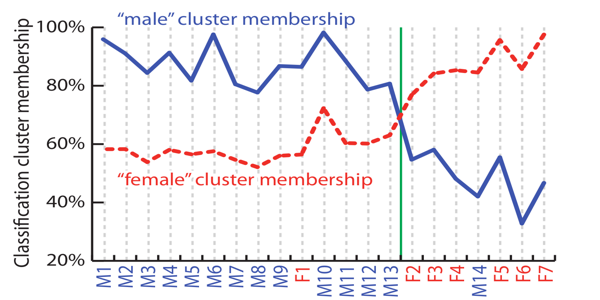
Metrics measuring differences between skeletal animation frames (poses) form the core of a large number of modern computer animation methods. A metric that accurately characterizes human motion perception could provide great advantages for these methods, by allowing the systems to focus exclusively on perceptually important aspects of the motion. In this paper we present a metric for human locomotion comparison, derived directly from the results of a perceptual experiment.
Most of the commonly used approaches for editing human motion, such as motion graphs and motion blending, use some form of distance metric in order to compare character poses in keyframes. These metrics utilize a combination of three traditional methods – joint angular differences, dis- tances between points on an object and velocities of specified bodyparts. The presented method attempts to find a metric and its parameters (not limited to the usual Euclidean metric), which would match a dataset formed by a direct perceptual experiment as closely as possible. Previous meth- ods used peception for evaluation alone, but we use perception as the basis of our metric.

We demonstrate the feasibility of rendering fur directly into existing images, without the need to either painstakingly paint over all pixels, or to supply 3D geometry and lighting. We add fur to objects depicted in images by first estimating depth and lighting information and then re-rendering the resulting 2.5D geometry with fur. A brush-based interface is provided, allowing the user to control the positioning and appearance of fur, while all the interaction takes place in a 2D pipeline. The novelty of this approach lies in the fact that a complex, high-level image edit such as the addition of fur can yield perceptually plausible results, even in the presence of imperfect depth or lighting information.

The aim of this thesis is to demonstrate the feasibility of rendering fur directly into existing images without the need to either painstakingly paint over all pixels, or to supply 3D geometry and lighting. The fur is added to objects depicted on images by first recovering depth and lighting information, and then re-rendering the resulting 2.5D geometry with fur. The novelty of this approach lies in the fact that complex high-level image edits, such as the addition of fur, can successfully yield perceptually plausible results, even constrained by imperfect depth and lighting information. A relatively large set of techniques involved in this work includes HDR imaging, shape-from-shading techniques, research on shape and lighting perception in images and photorealistic rendering techniques. The main purpose of this thesis is to prove the concept of the described approach. The main implementation language was C++ with usage of wxWidgets, OpenGL and libTIFF libraries, rendering was realised in 3Delight, a Renderman-compatible renderer, with the help of a set of custom shaders written in Renderman shading language.
About Me
R&D Supervisor at DNEG, with particular interest in crowd simulation and data-driven character animation. I have 7 years of experience in the VFX industry, and hold a PhD in computer science (specialised in data-driven character animation for crowd simulation).
London, UK